Meta has launched Llama 3 and claims it is among the greatest OpenGL fashions out there
5 min readMeta has Issued The newest entry in its Llama sequence of open supply generative AI fashions: Llama 3. Or, extra precisely, the corporate has open sourced two fashions in its new Llama 3 household, with the remainder arriving at an unspecified future date.
Meta describes the brand new fashions – Llama 3 8B, which has 8 billion parameters, and Llama 3 70B, which has 70 billion parameters – as a “big leap” in comparison with the earlier technology Llama fashions, Llama 2 8B and Llama 2 70B. In type of. In phrases of efficiency. (Parameters basically outline an AI mannequin’s ability at an issue, equivalent to analyzing and producing textual content; higher-parameter-count fashions are, typically talking, extra succesful than lower-parameter-count fashions.) .) In truth, Meta says that, no matter their respective parameters, Llama 3 8b and Llama 3 70b – Trained on two custom-built 24,000 GPU clusters – are are among the many greatest performing generic AI fashions out there at the moment.
This is precisely like making a declare. So how is Meta supporting this? Well, the corporate scores on widespread AI benchmarks like MMLU (which makes an attempt to measure information), ARC (which makes an attempt to measure ability acquisition) and DROP (which exams a mannequin’s logic on fragments of textual content). 3 signifies the rating of the mannequin. As we have now written earlier than, the usefulness – and validity – of those benchmarks is up for debate. But for higher or worse, they’re one of many few standardized strategies by which AI gamers like Meta consider their fashions.
Lama 3 8B is one of the best amongst different open supply fashions like Mistral mistral 7b and Google’s Gemma 7BBoth embody 7 billion parameters on not less than 9 benchmarks: MMLU, ARC, DROP, GPQA (a set of biology-, physics- and chemistry-related questions), HumanEval (a code technology take a look at), GSM-8K. (math phrase issues), MATH (one other math benchmark), AGIEval (a problem-solving take a look at set) and BIG-Bench Hard (a basic information reasoning evaluation).
Now, the Mistral 7B and Gemma 7B aren’t in unhealthy form in any respect (Mistral 7B was launched final September), and in some benchmarks reported by Meta, the Llama 3 8B scores just a few proportion factors larger than each . But Meta additionally claims that the larger-parameter-compute Llama 3 mannequin, Llama 3 70B, is aggressive with main generative AI fashions in Google’s Gemini sequence, together with the most recent Gemini 1.5 Pro.
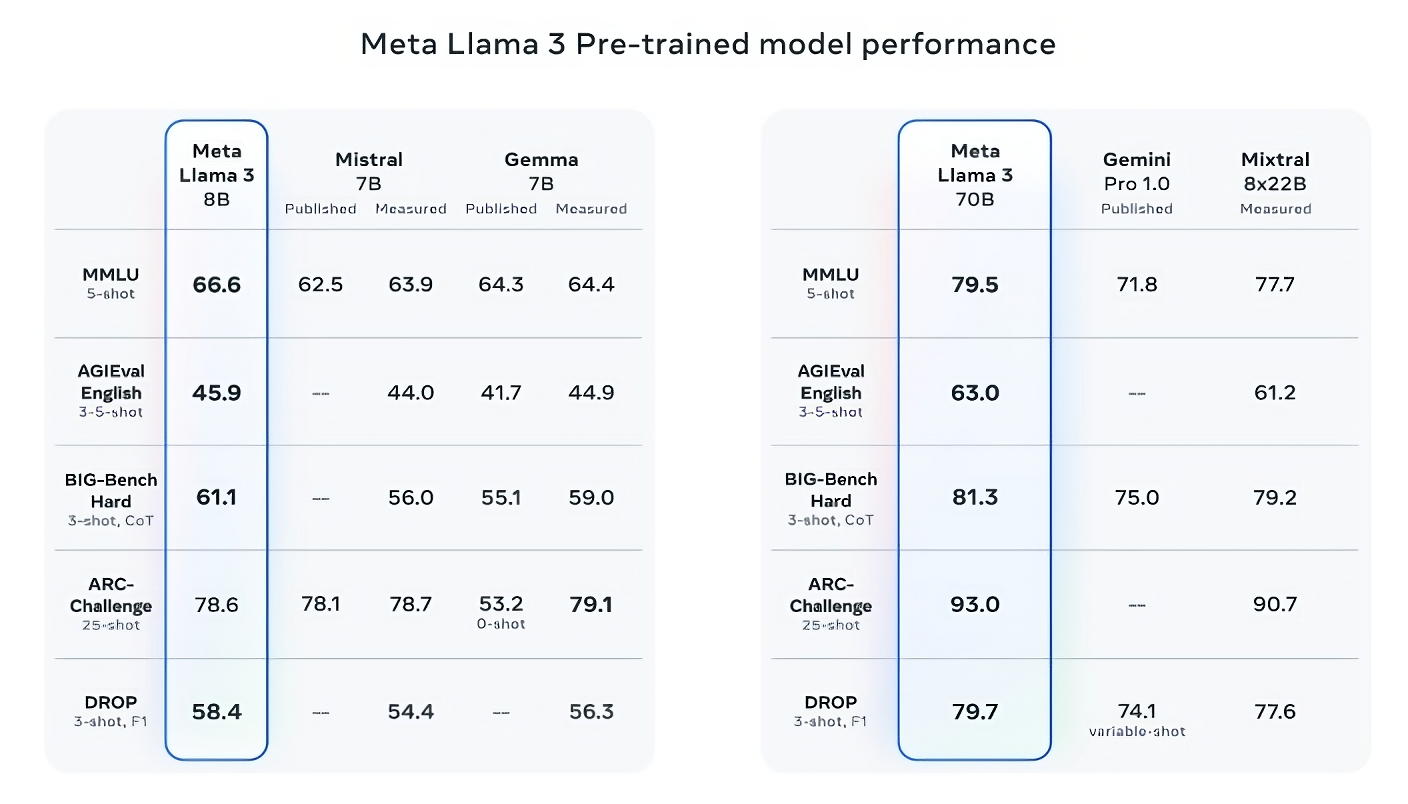
Image Credit: meta
The Llama 3 70B beats the Gemini 1.5 Pro on MMLU, HumanEval, and GSM-8K, and – whereas it would not rival Anthropic’s greatest mannequin, the Cloud 3 Opus – the Llama 3 70B’s rating is the weakest of the Cloud 3 sequence. The mannequin is healthier than Cloud 3. SONET,on 5 benchmarks (MMLU, GPQA, HumanEval, GSM-8K and MATH).
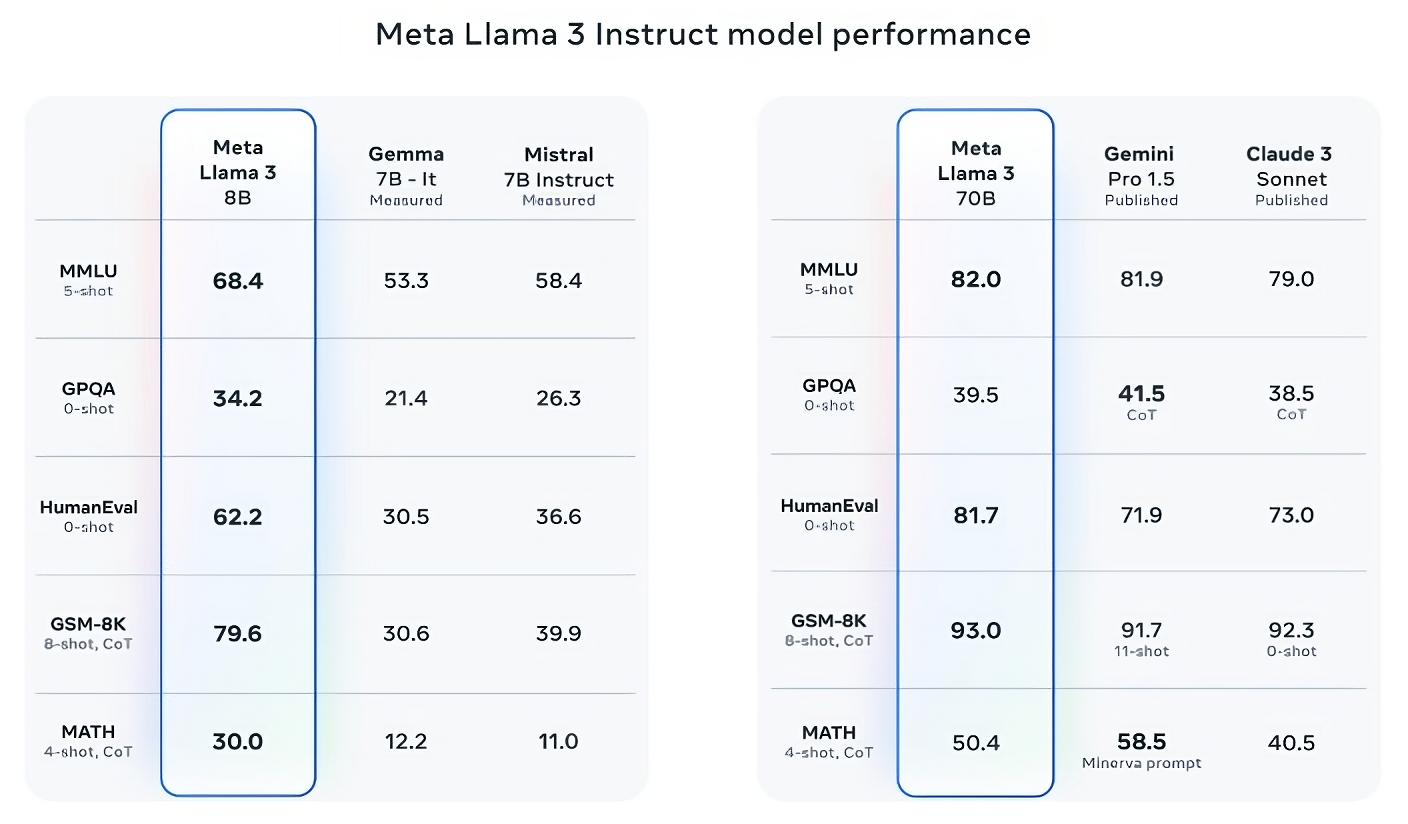
Image Credit: meta
For what it is price, Meta has additionally developed its personal take a look at set that covers use circumstances starting from coding and writing to logic to summarization, and – shock! — Llama 3 70B got here out on prime towards Mistral’s Mistral Medium mannequin, OpenAI’s GPT-3.5, and Cloud Sonnet. Meta says it has blocked its modeling groups from accessing the set to take care of objectivity, however clearly – provided that Meta designed the take a look at itself – the outcomes need to be taken with a grain of salt.

Image Credit: meta
More qualitatively, Meta says customers of the brand new Llama mannequin ought to anticipate better “maneuverability”, much less probability of refusing to reply questions, and extra flexibility normally information questions, historical past, and STEM fields equivalent to engineering and science. And excessive accuracy on basic coding associated questions. Recommendations. This is partly because of the very giant information set: a group of 15 trillion tokens, or an astonishing ~750,000,000,000 phrases – seven occasions the dimensions of the Llama 2 coaching set. (In the AI discipline, “token” refers to subdivided bits of uncooked information, such because the syllables “fan,” “toss,” and “tick” within the phrase “fantastic.”)
Where did this information come from? Good query. The meta will not reveal why, solely disclosing that it’s taken from “publicly available sources”, incorporates 4 occasions extra code than the Llama 2 coaching information set, and that 5% of that set incorporates non-English. There is information (~30 languages) to enhance efficiency on languages apart from English. Meta additionally stated it has used artificial information – that’s, AI-generated information – to create longer paperwork to coach Llama 3 fashions. considerably controversial viewpoint Due to potential efficiency deficiencies.
Meta writes in a weblog put up shared with TechCrunch, “Although the models we are releasing today are fine-tuned only for English output, the increased data diversity will allow the models to better recognize nuances and patterns and respond to different “Helps one carry out strongly in quite a lot of duties.”
Many generic AI distributors view coaching information as a aggressive benefit and thus retain it and associated info. But coaching information particulars are additionally a possible supply of IP-related lawsuits, which is one other disincentive to revealing an excessive amount of. latest reporting It was revealed that Meta, in its quest to maintain tempo with AI rivals, had at one time used copyrighted eBooks for AI coaching, regardless of warnings from the corporate’s personal legal professionals; Meta and OpenAI are the topic of an ongoing lawsuit introduced by authors together with comic Sarah Silverman over alleged unauthorized use of copyrighted information for coaching by the distributors.
So what about toxicity and bias, two different widespread issues with generative AI fashions (together with llama 2, Does the Llama 3 enhance in these areas? Yes, claims Meta.
Meta says it has developed new data-filtering pipelines to spice up the standard of its mannequin coaching information, and it has launched generative AI safety suites, Llama Guard and Have up to date your pair of cybersavage. 3 fashions and others. The firm can be releasing a brand new device, Code Shield, designed to detect code from generative AI fashions that might introduce safety vulnerabilities.
However, filtering is not foolproof – and instruments like Llama Guard, CyberSeal, and Code Shield solely go to date. (See: Llama Tendency 2 Create solutions to questions and leak non-public well being and monetary info.) We’ll have to attend and see how the Llama 3 fashions carry out within the wild on various benchmarks, together with testing from teachers.
Meta says the Llama 3 fashions — which can be found for obtain now, and energy Meta’s Meta AI assistant on Facebook, Instagram, WhatsApp, Messenger, and the online — will quickly be managed throughout a variety of cloud platforms, together with AWS. Will be hosted as. Databricks, Google Cloud, Hugging Face, Kaggle, IBM’s WatsonX, Microsoft Azure, Nvidia’s NIM and Snowflake. In the longer term, variations of the mannequin optimized for {hardware} from AMD, AWS, Dell, Intel, Nvidia, and Qualcomm may also be made out there.
More succesful fashions are on the horizon.
Meta says it’s at present coaching Llama 3 fashions with greater than 400 billion form parameters – fashions which have the flexibility to “conversate in multiple languages”, absorb extra information and combine photographs and different info. Understand the strategies in addition to the teachings that the Lama 3 sequence will convey. Compatible with open releases like hugging face ideology2,

Image Credit: meta
“Our goal in the near future is to make Llama 3 multilingual and multimodal, have a longer context, and continue to improve overall performance in core (large language model) capabilities like logic and coding,” Meta writes in a weblog put up. “There is still more to come.”
In truth.
